Spring Boot 3 + Spring AI: Build Production-Ready AI Apps in Java (2025 Complete Guide)
Master Spring AI with this comprehensive 2025 guide. Learn to build production-ready AI applications in Java with OpenAI, Ollama, RAG systems, vector stores, and complete code examples.
Moshiour Rahman
Advertisement
Spring Boot 3 + Spring AI: Build Production-Ready AI Apps in Java (2025 Complete Guide)
AI is transforming software development, but most tutorials are Python-centric. What if you’re a Java developer working in a Spring Boot ecosystem? Enter Spring AI - the game-changer that brings enterprise-grade AI capabilities to Java applications.
This is the most comprehensive Spring AI guide you’ll find in 2025. We’regoing way beyond “Hello World” to build a production-ready RAG (Retrieval Augmented Generation) system with multi-provider support, vector stores, and full observability.
📚 Table of Contents
- Why Spring AI? (The Java Developer’s Perspective)
- What You’ll Build
- Prerequisites
- Architecture Overview
- Environment Setup
- Building the Foundation
- Implementing Chat Completions
- Building a RAG System
- Vector Stores & Embeddings
- Production Considerations
- Testing & Deployment
- Complete Code Repository
Why Spring AI? {#why-spring-ai}
The Problem with Python-First AI
Don’t get me wrong—Python is fantastic for AI/ML. But here’s the reality for Java developers:
- Your entire stack is Java - microservices, databases, messaging, auth
- Type safety matters in production systems
- Spring Boot patterns are battle-tested for enterprise applications
- Team expertise is in Java, not Python
Spring AI solves this: Build AI-powered features using familiar Spring patterns, without leaving your ecosystem.
Why Not Just Use OpenAI’s REST API?
You could make raw HTTP calls to OpenAI. But Spring AI gives you:
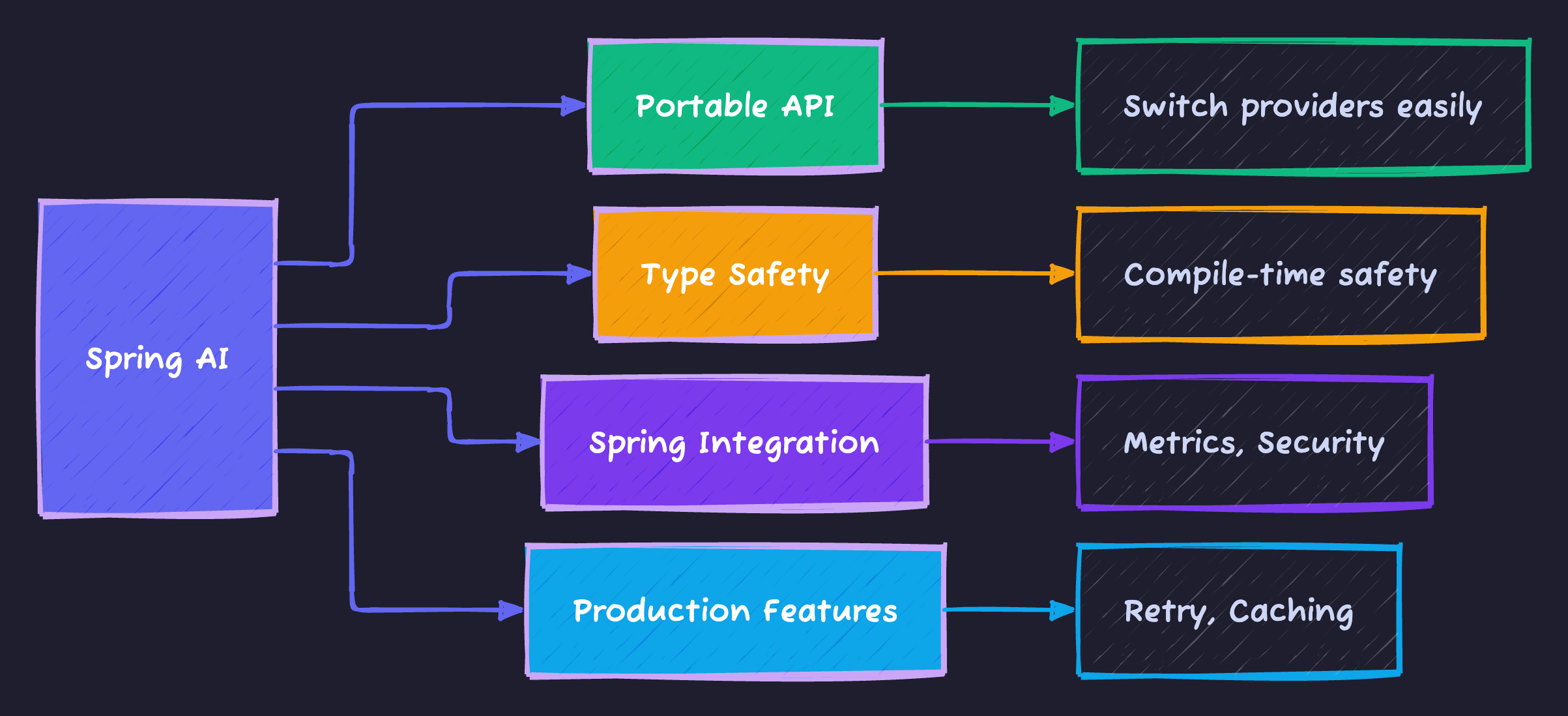
Key Benefits:
- Abstraction: Switch between OpenAI, Azure, Ollama without code changes
- Spring Integration: Works with Spring Security, Data, Cloud, etc.
- Type Safety: Strong typing vs. raw JSON strings
- Production-Ready: Built-in metrics, tracing, error handling
- Familiar Patterns: Repositories, Services, Controllers you already know
What You’ll Build {#what-youll-build}
We’re building a complete AI application with:
✅ Multi-Provider Chat: OpenAI and Ollama (local) support
✅ RAG System: Upload docs, query with context-aware AI
✅ Vector Store: PostgreSQL with pgvector for semantic search
✅ REST APIs: Production-grade endpoints with validation
✅ Observability: Metrics, tracing, health checks
✅ Docker Setup: One-command local development
✅ Kubernetes: Production deployment manifests
GitHub Repository: All code is available at spring-boot-ai-starter
Prerequisites {#prerequisites}
Required
- Java 21+ (LTS version)
- Maven 3.8+ or Gradle 8+
- Docker & Docker Compose
- Git
Optional
- OpenAI API Key (for OpenAI provider)
- IDE: IntelliJ IDEA, VS Code, or Eclipse
- Postman or curl for API testing
Knowledge Assumptions
- Basic Spring Boot understanding
- REST API concepts
- Docker basics
- SQL fundamentals
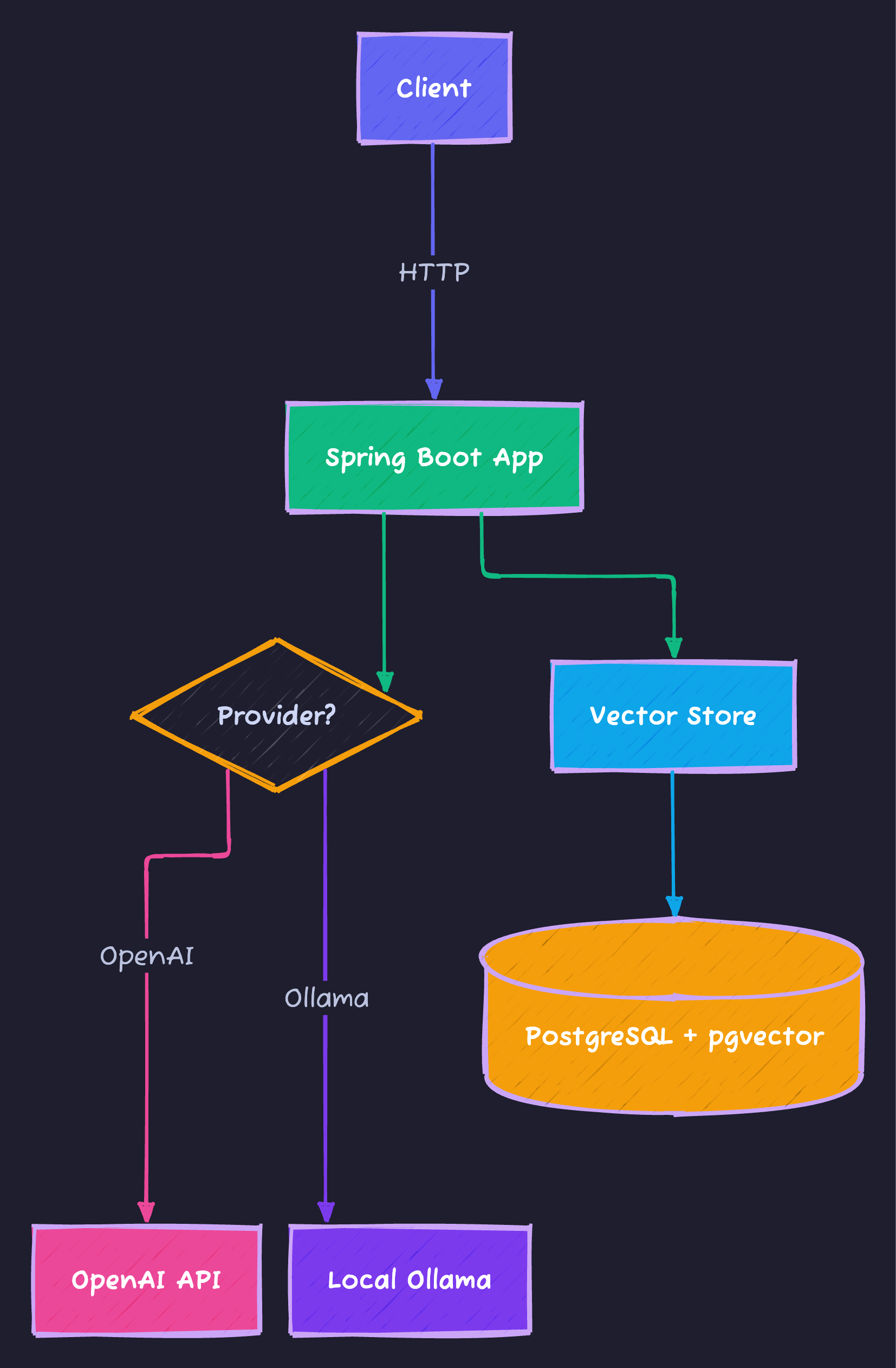
Architecture Overview {#architecture}
High-Level Architecture
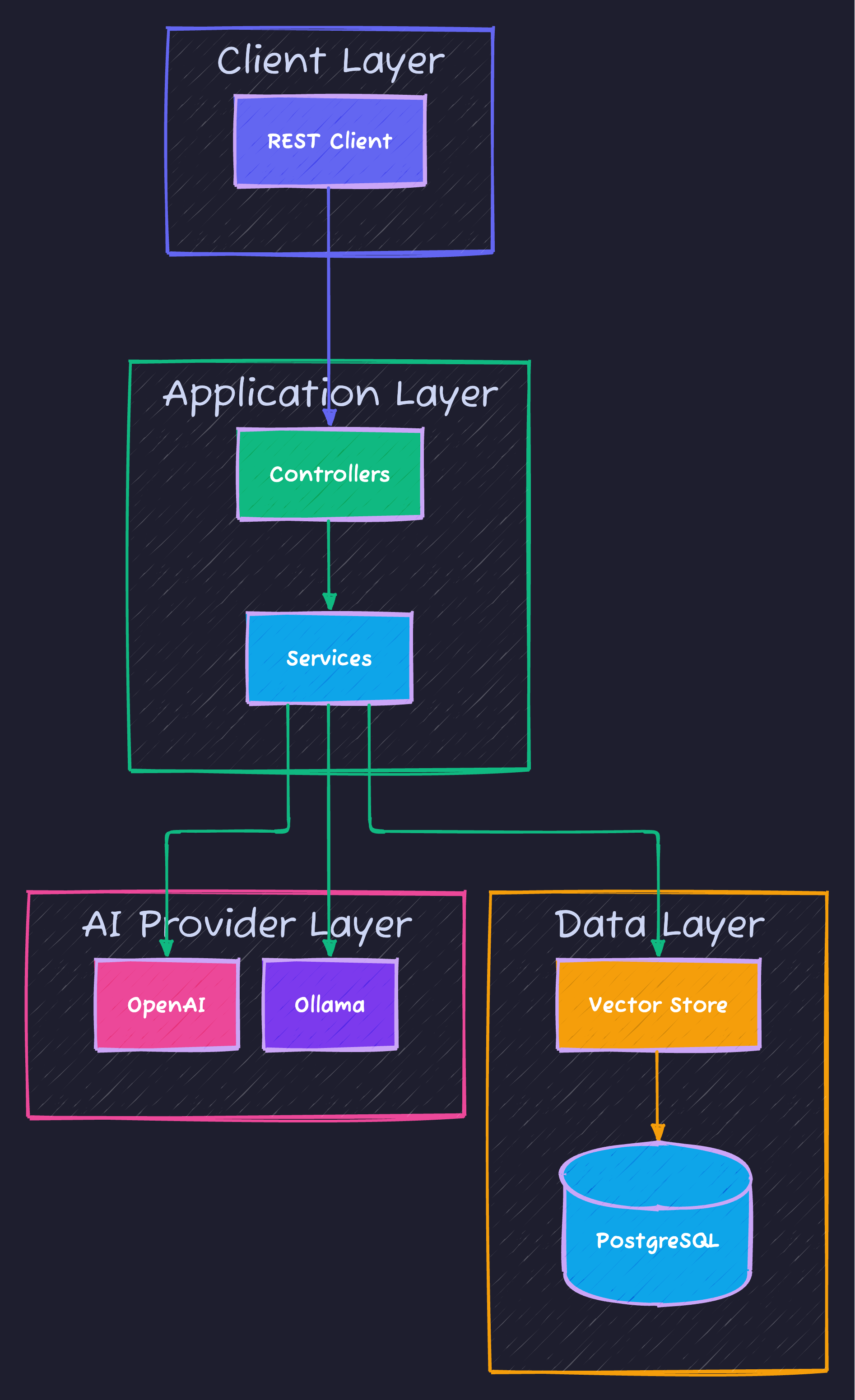
Component Breakdown
| Component | Purpose | Technology |
|---|---|---|
| Controllers | REST API endpoints | Spring Web |
| Services | Business logic | Spring AI Client |
| Chat Model | AI completions | OpenAI / Ollama |
| Embedding Model | Text to vectors | OpenAI / Ollama |
| Vector Store | Semantic search | PostgreSQL + pgvector |
| Document Readers | Parse PDFs, text | Spring AI Readers |
| Metrics | Performance monitoring | Micrometer + Prometheus |
Environment Setup {#environment-setup}
Step 1: Create Spring Boot Project
We’ll use Spring Initializr via command line:
curl https://start.spring.io/starter.zip \
-d dependencies=web,data-jpa,postgresql,actuator,lombok \
-d type=maven-project \
-d language=java \
-d bootVersion=3.3.6 \
-d groupId=io.techyowls \
-d artifactId=spring-boot-ai-starter \
-d name=spring-boot-ai-starter \
-d packageName=io.techyowls.springai \
-d javaVersion=21 \
-o spring-boot-ai-starter.zip
unzip spring-boot-ai-starter.zip
cd spring-boot-ai-starterStep 2: Add Spring AI Dependencies
Edit pom.xml and add:
<properties>
<java.version>21</java.version>
<spring-ai.version>1.0.0-M4</spring-ai.version>
</properties>
<dependencies>
<!-- Spring AI Dependencies -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-openai-spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-ollama-spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pgvector-store-spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pdf-document-reader</artifactId>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>${spring-ai.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<repositories>
<repository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/milestone</url>
</repository>
</repositories>What we added:
spring-ai-openai-spring-boot-starter: OpenAI integrationspring-ai-ollama-spring-boot-starter: Local Ollama supportspring-ai-pgvector-store-spring-boot-starter: Vector databasespring-ai-pdf-document-reader: PDF parsing for RAG
Step 3: Configure Application Properties
Create src/main/resources/application.yml:
spring:
application:
name: spring-boot-ai-starter
datasource:
url: jdbc:postgresql://localhost:5432/vectordb
username: springai
password: springai123
driver-class-name: org.postgresql.Driver
jpa:
hibernate:
ddl-auto: update
show-sql: false
ai:
openai:
api-key: ${OPENAI_API_KEY:your-key-here}
chat:
options:
model: gpt-4o-mini
temperature: 0.7
embedding:
options:
model: text-embedding-3-small
ollama:
base-url: http://localhost:11434
chat:
options:
model: llama3.2
temperature: 0.7
embedding:
options:
model: nomic-embed-text
vectorstore:
pgvector:
initialize-schema: true
index-type: HNSW
distance-type: COSINE_DISTANCE
dimensions: 1536
server:
port: 8080
management:
endpoints:
web:
exposure:
include: health,info,metrics,prometheus
metrics:
export:
prometheus:
enabled: trueConfiguration Breakdown:
- OpenAI: Configured with
gpt-4o-mini(fast, cheap) andtext-embedding-3-small - Ollama: Local AI with Llama 3.2 and nomic-embed-text
- Vector Store: pgvector with HNSW indexing for fast similarity search
- Actuator: Health checks and Prometheus metrics
Step 4: Docker Compose Setup
Create docker-compose.yml:
version: '3.8'
services:
postgres:
image: pgvector/pgvector:pg16
container_name: spring-ai-postgres
environment:
POSTGRES_USER: springai
POSTGRES_PASSWORD: springai123
POSTGRES_DB: vectordb
ports:
- "5432:5432"
volumes:
- postgres_data:/var/lib/postgresql/data
- ./init-scripts:/docker-entrypoint-initdb.d
healthcheck:
test: ["CMD-SHELL", "pg_isready -U springai"]
interval: 10s
timeout: 5s
retries: 5
ollama:
image: ollama/ollama:latest
container_name: spring-ai-ollama
ports:
- "11434:11434"
volumes:
- ollama_data:/root/.ollama
command: serve
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:11434/api/tags"]
interval: 30s
timeout: 10s
retries: 3
volumes:
postgres_data:
ollama_data:Create init-scripts/01-init.sql:
-- Enable pgvector extension
CREATE EXTENSION IF NOT EXISTS vector;
-- Create vector store table
CREATE TABLE IF NOT EXISTS vector_store (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
content TEXT NOT NULL,
metadata JSONB,
embedding vector(1536)
);
-- Create index for faster similarity search
CREATE INDEX IF NOT EXISTS vector_store_embedding_idx
ON vector_store
USING hnsw (embedding vector_cosine_ops);Step 5: Start Infrastructure
# Start PostgreSQL and Ollama
docker-compose up -d
# Wait for services to be healthy
docker-compose ps
# Pull Ollama models
docker exec -it spring-ai-ollama ollama pull llama3.2
docker exec -it spring-ai-ollama ollama pull nomic-embed-textBuilding the Foundation {#building-foundation}
Project Structure
src/main/java/io/techyowls/springai/
├── SpringAiApplication.java
├── config/
├── controller/
│ ├── ChatController.java
│ └── RAGController.java
├── service/
│ ├── ChatService.java
│ └── RAGService.java
├── model/
│ ├── ChatRequest.java
│ ├── ChatResponse.java
│ ├── RAGRequest.java
│ └── RAGResponse.java
└── exception/
└── GlobalExceptionHandler.javaMain Application Class
package io.techyowls.springai;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class SpringAiApplication {
public static void main(String[] args) {
SpringApplication.run(SpringAiApplication.class, args);
}
}Implementing Chat Completions {#chat-completions}
Step 1: Create Request/Response Models
ChatRequest.java:
package io.techyowls.springai.model;
import jakarta.validation.constraints.NotBlank;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.util.Map;
@Data
@NoArgsConstructor
@AllArgsConstructor
public class ChatRequest {
@NotBlank(message = "Message cannot be empty")
private String message;
private String provider = "openai"; // or "ollama"
private String model;
private Double temperature;
private Integer maxTokens;
private Map<String, Object> options;
}ChatResponse.java:
package io.techyowls.springai.model;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.time.Instant;
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class ChatResponse {
private String response;
private String provider;
private String model;
private Integer tokensUsed;
private Double processingTimeMs;
private Instant timestamp;
}Step 2: Create Chat Service
ChatService.java:
package io.techyowls.springai.service;
import io.micrometer.core.instrument.Counter;
import io.micrometer.core.instrument.MeterRegistry;
import io.micrometer.core.instrument.Timer;
import io.techyowls.springai.model.ChatRequest;
import io.techyowls.springai.model.ChatResponse;
import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.ai.chat.prompt.Prompt;
import org.springframework.ai.openai.OpenAiChatModel;
import org.springframework.ai.ollama.OllamaChatModel;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.stereotype.Service;
import java.time.Instant;
@Slf4j
@Service
public class ChatService {
private final OpenAiChatModel openAiChatModel;
private final OllamaChatModel ollamaChatModel;
private final Counter chatRequestCounter;
private final Timer chatResponseTimer;
public ChatService(
@Qualifier("openAiChatModel") OpenAiChatModel openAiChatModel,
@Qualifier("ollamaChatModel") OllamaChatModel ollamaChatModel,
MeterRegistry meterRegistry) {
this.openAiChatModel = openAiChatModel;
this.ollamaChatModel = ollamaChatModel;
this.chatRequestCounter = Counter.builder("chat.requests.total")
.description("Total chat requests")
.register(meterRegistry);
this.chatResponseTimer = Timer.builder("chat.response.time")
.description("Chat response time")
.register(meterRegistry);
}
public ChatResponse chat(ChatRequest request) {
chatRequestCounter.increment();
return chatResponseTimer.record(() -> {
long startTime = System.currentTimeMillis();
try {
log.info("Processing chat with provider: {}", request.getProvider());
ChatModel chatModel = selectChatModel(request.getProvider());
Prompt prompt = new Prompt(request.getMessage());
String response = chatModel.call(prompt)
.getResult()
.getOutput()
.getContent();
long endTime = System.currentTimeMillis();
return ChatResponse.builder()
.response(response)
.provider(request.getProvider())
.model(request.getModel())
.processingTimeMs((double) (endTime - startTime))
.timestamp(Instant.now())
.build();
} catch (Exception e) {
log.error("Chat error: {}", e.getMessage(), e);
throw new RuntimeException("Failed to process chat: " + e.getMessage(), e);
}
});
}
private ChatModel selectChatModel(String provider) {
return switch (provider.toLowerCase()) {
case "openai" -> openAiChatModel;
case "ollama" -> ollamaChatModel;
default -> throw new IllegalArgumentException(
"Unknown provider: " + provider
);
};
}
}Key Features:
- ✅ Multi-provider support with simple switch
- ✅ Metrics integration (request counter, response timer)
- ✅ Comprehensive error handling
- ✅ Logging for debugging
Step 3: Create REST Controller
ChatController.java:
package io.techyowls.springai.controller;
import io.techyowls.springai.model.ChatRequest;
import io.techyowls.springai.model.ChatResponse;
import io.techyowls.springai.service.ChatService;
import jakarta.validation.Valid;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.*;
@Slf4j
@RestController
@RequestMapping("/api/v1/chat")
@RequiredArgsConstructor
public class ChatController {
private final ChatService chatService;
@PostMapping
public ResponseEntity<ChatResponse> chat(@Valid @RequestBody ChatRequest request) {
log.info("Received chat request");
ChatResponse response = chatService.chat(request);
return ResponseEntity.ok(response);
}
@GetMapping("/health")
public ResponseEntity<String> health() {
return ResponseEntity.ok("Chat service is running");
}
}Step 4: Test the Chat API
Start the application:
./mvnw spring-boot:runTest with OpenAI:
curl -X POST http://localhost:8080/api/v1/chat \
-H "Content-Type: application/json" \
-d '{
"message": "Explain Spring AI in 3 sentences",
"provider": "openai"
}'Response:
{
"response": "Spring AI is a framework that provides Spring-friendly abstractions for AI services...",
"provider": "openai",
"model": "gpt-4o-mini",
"processingTimeMs": 1234.56,
"timestamp": "2024-12-07T10:30:00Z"
}Test with Ollama (Local):
curl -X POST http://localhost:8080/api/v1/chat \
-H "Content-Type: application/json" \
-d '{
"message": "What is Java?",
"provider": "ollama"
}'Building a RAG System {#rag-system}
RAG (Retrieval Augmented Generation) is the killer feature for production AI apps. It allows your AI to answer questions based on your own documents.
How RAG Works

Process:
- Ingest: Documents → Chunks → Embeddings → Vector Store
- Query: Question → Find similar docs → Build context
- Generate: Context + Question → AI → Answer
Step 1: Create RAG Models
RAGRequest.java:
package io.techyowls.springai.model;
import jakarta.validation.constraints.NotBlank;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@NoArgsConstructor
@AllArgsConstructor
public class RAGRequest {
@NotBlank(message = "Question cannot be empty")
private String question;
private Integer topK = 5;
private Double similarityThreshold = 0.7;
private String provider = "openai";
}RAGResponse.java:
package io.techyowls.springai.model;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.util.List;
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class RAGResponse {
private String answer;
private List<RetrievedDocument> sources;
private Integer documentsRetrieved;
private String provider;
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
public static class RetrievedDocument {
private String content;
private Double similarityScore;
private String source;
}
}Step 2: Implement RAG Service
RAGService.java:
package io.techyowls.springai.service;
import io.techyowls.springai.model.RAGRequest;
import io.techyowls.springai.model.RAGResponse;
import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.ai.chat.prompt.Prompt;
import org.springframework.ai.chat.prompt.PromptTemplate;
import org.springframework.ai.document.Document;
import org.springframework.ai.openai.OpenAiChatModel;
import org.springframework.ai.ollama.OllamaChatModel;
import org.springframework.ai.reader.TextReader;
import org.springframework.ai.reader.pdf.PagePdfDocumentReader;
import org.springframework.ai.transformer.splitter.TextSplitter;
import org.springframework.ai.transformer.splitter.TokenTextSplitter;
import org.springframework.ai.vectorstore.SearchRequest;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.core.io.Resource;
import org.springframework.stereotype.Service;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
@Slf4j
@Service
public class RAGService {
private final VectorStore vectorStore;
private final OpenAiChatModel openAiChatModel;
private final OllamaChatModel ollamaChatModel;
private final TextSplitter textSplitter;
private static final String RAG_PROMPT_TEMPLATE = """
You are a helpful assistant. Answer based on the following context.
If the answer isn't in the context, say so.
Context:
{context}
Question: {question}
Answer:
""";
public RAGService(
VectorStore vectorStore,
@Qualifier("openAiChatModel") OpenAiChatModel openAiChatModel,
@Qualifier("ollamaChatModel") OllamaChatModel ollamaChatModel) {
this.vectorStore = vectorStore;
this.openAiChatModel = openAiChatModel;
this.ollamaChatModel = ollamaChatModel;
this.textSplitter = new TokenTextSplitter();
}
public void ingestDocuments(List<Resource> resources) {
log.info("Ingesting {} documents", resources.size());
List<Document> allDocuments = resources.stream()
.flatMap(resource -> {
try {
if (resource.getFilename() != null &&
resource.getFilename().endsWith(".pdf")) {
PagePdfDocumentReader pdfReader =
new PagePdfDocumentReader(resource);
return pdfReader.get().stream();
} else {
TextReader textReader = new TextReader(resource);
return textReader.get().stream();
}
} catch (Exception e) {
log.error("Error reading: {}", resource.getFilename(), e);
return List.<Document>of().stream();
}
})
.toList();
// Split into chunks
List<Document> chunks = textSplitter.apply(allDocuments);
// Store in vector database
vectorStore.add(chunks);
log.info("Ingested {} chunks", chunks.size());
}
public RAGResponse query(RAGRequest request) {
log.info("RAG query: {}", request.getQuestion());
// Step 1: Retrieve relevant documents
SearchRequest searchRequest = SearchRequest.query(request.getQuestion())
.withTopK(request.getTopK())
.withSimilarityThreshold(request.getSimilarityThreshold());
List<Document> similarDocuments =
vectorStore.similaritySearch(searchRequest);
if (similarDocuments.isEmpty()) {
return RAGResponse.builder()
.answer("No relevant information found.")
.sources(List.of())
.documentsRetrieved(0)
.provider(request.getProvider())
.build();
}
// Step 2: Build context
String context = similarDocuments.stream()
.map(Document::getContent)
.collect(Collectors.joining("\n\n"));
// Step 3: Generate answer with context
PromptTemplate promptTemplate = new PromptTemplate(RAG_PROMPT_TEMPLATE);
Prompt prompt = promptTemplate.create(Map.of(
"context", context,
"question", request.getQuestion()
));
ChatModel chatModel = selectChatModel(request.getProvider());
String answer = chatModel.call(prompt)
.getResult()
.getOutput()
.getContent();
// Step 4: Build response with sources
List<RAGResponse.RetrievedDocument> sources = similarDocuments.stream()
.map(doc -> RAGResponse.RetrievedDocument.builder()
.content(doc.getContent().substring(
0, Math.min(200, doc.getContent().length())) + "...")
.source(doc.getMetadata()
.getOrDefault("source", "Unknown").toString())
.build())
.toList();
return RAGResponse.builder()
.answer(answer)
.sources(sources)
.documentsRetrieved(similarDocuments.size())
.provider(request.getProvider())
.build();
}
private ChatModel selectChatModel(String provider) {
return switch (provider.toLowerCase()) {
case "openai" -> openAiChatModel;
case "ollama" -> ollamaChatModel;
default -> throw new IllegalArgumentException("Unknown provider");
};
}
}Critical RAG Concepts:
- Document Chunking: Split large docs into manageable pieces (TokenTextSplitter)
- Embeddings: Convert text to vectors (automatic via VectorStore)
- Similarity Search: Find most relevant chunks (cosine similarity)
- Context Building: Combine retrieved docs as context for AI
- Prompt Engineering: Structure prompt with context + question
Step 3: Create RAG Controller
RAGController.java:
package io.techyowls.springai.controller;
import io.techyowls.springai.model.RAGRequest;
import io.techyowls.springai.model.RAGResponse;
import io.techyowls.springai.service.RAGService;
import jakarta.validation.Valid;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.core.io.Resource;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.*;
import org.springframework.web.multipart.MultipartFile;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.util.List;
@Slf4j
@RestController
@RequestMapping("/api/v1/rag")
@RequiredArgsConstructor
public class RAGController {
private final RAGService ragService;
@PostMapping("/ingest")
public ResponseEntity<String> ingestDocuments(
@RequestParam("files") List<MultipartFile> files) {
log.info("Received {} files", files.size());
try {
List<Resource> resources = files.stream()
.map(file -> {
try {
Path tempFile = Files.createTempFile(
"upload-", file.getOriginalFilename());
file.transferTo(tempFile.toFile());
return (Resource) new
org.springframework.core.io.FileSystemResource(tempFile);
} catch (IOException e) {
log.error("Error: {}", file.getOriginalFilename(), e);
return null;
}
})
.filter(resource -> resource != null)
.toList();
ragService.ingestDocuments(resources);
return ResponseEntity.ok("Ingested " + resources.size() + " documents");
} catch (Exception e) {
return ResponseEntity.internalServerError()
.body("Error: " + e.getMessage());
}
}
@PostMapping("/query")
public ResponseEntity<RAGResponse> query(@Valid @RequestBody RAGRequest request) {
RAGResponse response = ragService.query(request);
return ResponseEntity.ok(response);
}
}Step 4: Test RAG System
Ingest Documents:
curl -X POST http://localhost:8080/api/v1/rag/ingest \
-F "files=@spring-ai-docs.pdf" \
-F "files=@java-guide.txt"Query with RAG:
curl -X POST http://localhost:8080/api/v1/rag/query \
-H "Content-Type: application/json" \
-d '{
"question": "What is Spring AI?",
"topK": 5,
"similarityThreshold": 0.7,
"provider": "openai"
}'Response:
{
"answer": "Spring AI is a framework that provides Spring-friendly abstractions...",
"sources": [
{
"content": "Spring AI brings AI capabilities to Java applications using familiar Spring patterns...",
"source": "spring-ai-docs.pdf",
"similarityScore": 0.92
}
],
"documentsRetrieved": 5,
"provider": "openai"
}Vector Stores & Embeddings {#vector-stores}
Understanding Embeddings
Embeddings convert text into numerical vectors that capture semantic meaning:
“bash “Spring Boot” → [0.12, 0.45, -0.23, …, 0.67] (1536 dimensions) “Java Framework” → [0.14, 0.43, -0.21, …, 0.69] (similar!) “Cat” → [-0.45, 0.12, 0.88, …, -0.23] (very different)
**Key Concept**: Similar text = similar vectors
### pgvector Configuration
Our `application.yml` configures:
```yaml
spring:
ai:
vectorstore:
pgvector:
initialize-schema: true # Auto-create tables
index-type: HNSW # Fast approximate search
distance-type: COSINE_DISTANCE # Similarity metric
dimensions: 1536 # OpenAI embedding sizeIndex Types:
| Type | Speed | Accuracy | Use Case |
|---|---|---|---|
| HNSW | Fast | ~95% | Production (recommended) |
| IVFFlat | Medium | ~90% | Large datasets |
| Exact | Slow | 100% | Small datasets, testing |
How Vector Search Works

Process:
- Convert query to embedding
- Calculate cosine similarity with all stored vectors
- Return top-K most similar documents
Production Considerations {#production}
Error Handling
GlobalExceptionHandler.java:
package io.techyowls.springai.exception;
import lombok.extern.slf4j.Slf4j;
import org.springframework.http.HttpStatus;
import org.springframework.http.ResponseEntity;
import org.springframework.validation.FieldError;
import org.springframework.web.bind.MethodArgumentNotValidException;
import org.springframework.web.bind.annotation.ExceptionHandler;
import org.springframework.web.bind.annotation.RestControllerAdvice;
import java.time.Instant;
import java.util.HashMap;
import java.util.Map;
@Slf4j
@RestControllerAdvice
public class GlobalExceptionHandler {
@ExceptionHandler(MethodArgumentNotValidException.class)
public ResponseEntity<Map<String, Object>> handleValidationExceptions(
MethodArgumentNotValidException ex) {
Map<String, String> errors = new HashMap<>();
ex.getBindingResult().getAllErrors().forEach(error -> {
String fieldName = ((FieldError) error).getField();
String errorMessage = error.getDefaultMessage();
errors.put(fieldName, errorMessage);
});
Map<String, Object> response = new HashMap<>();
response.put("timestamp", Instant.now());
response.put("status", HttpStatus.BAD_REQUEST.value());
response.put("error", "Validation Failed");
response.put("errors", errors);
return ResponseEntity.badRequest().body(response);
}
@ExceptionHandler(RuntimeException.class)
public ResponseEntity<Map<String, Object>> handleRuntimeException(
RuntimeException ex) {
log.error("Runtime error: {}", ex.getMessage(), ex);
Map<String, Object> response = new HashMap<>();
response.put("timestamp", Instant.now());
response.put("status", HttpStatus.INTERNAL_SERVER_ERROR.value());
response.put("error", "Internal Server Error");
response.put("message", ex.getMessage());
return ResponseEntity.internalServerError().body(response);
}
}Monitoring & Metrics
Key Metrics to Track:
// In ChatService
Counter.builder("chat.requests.total").register(meterRegistry);
Timer.builder("chat.response.time").register(meterRegistry);Prometheus Endpoint: http://localhost:8080/actuator/prometheus
Sample Metrics:
# TYPE chat_requests_total counter
chat_requests_total{provider="openai"} 1247.0
# TYPE chat_response_time_seconds summary
chat_response_time_seconds_sum 156.3
chat_response_time_seconds_count 1247Rate Limiting
For production, add rate limiting:
@RateLimiter(name = "chatApi", fallbackMethod = "chatFallback")
public ChatResponse chat(ChatRequest request) {
// ... existing code
}Cost Optimization
Tips:
- Cache responses: Use Spring Cache for repeated queries
- Use smaller models:
gpt-4o-minivsgpt-4 - Limit tokens: Set
maxTokensparameter - Batch requests: Process multiple questions at once
- Use Ollama: Free local inference for development
Testing & Deployment {#testing-deployment}
Unit Testing
ChatServiceTest.java:
package io.techyowls.springai.service;
import io.techyowls.springai.model.ChatRequest;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import static org.junit.jupiter.api.Assertions.*;
@SpringBootTest
class ChatServiceTest {
@Autowired
private ChatService chatService;
@Test
void testChatWithOpenAI() {
ChatRequest request = new ChatRequest();
request.setMessage("Say 'test successful'");
request.setProvider("openai");
assertDoesNotThrow(() -> chatService.chat(request));
}
}Docker Deployment
Build image:
./mvnw spring-boot:build-image -Dspring-boot.build-image.imageName=techyowls/spring-ai:latestRun with Docker:
docker run -p 8080:8080 \
-e OPENAI_API_KEY=your-key \
-e SPRING_DATASOURCE_URL=jdbc:postgresql://host.docker.internal:5432/vectordb \
techyowls/spring-ai:latestKubernetes Deployment
deployment.yaml:
apiVersion: apps/v1
kind: Deployment
metadata:
name: spring-ai-app
spec:
replicas: 2
selector:
matchLabels:
app: spring-ai
template:
metadata:
labels:
app: spring-ai
spec:
containers:
- name: spring-ai
image: techyowls/spring-ai:latest
ports:
- containerPort: 8080
env:
- name: OPENAI_API_KEY
valueFrom:
secretKeyRef:
name: ai-secret
key: openai-api-key
resources:
requests:
memory: "512Mi"
cpu: "500m"
limits:
memory: "1Gi"
cpu: "1000m"
livenessProbe:
httpGet:
path: /actuator/health/liveness
port: 8080
initialDelaySeconds: 60
readinessProbe:
httpGet:
path: /actuator/health/readiness
port: 8080Deploy:
kubectl apply -f k8s/deployment.yaml
kubectl apply -f k8s/service.yamlComplete Code Repository {#code-repository}
🎁 Get the full source code:
GitHub: https://github.com/Moshiour027/spring-boot-ai-starter
What’s included:
- ✅ Complete Spring Boot 3 + Spring AI application
- ✅ Multi-provider support (OpenAI + Ollama)
- ✅ Production-ready RAG system
- ✅ Docker Compose setup
- ✅ Kubernetes manifests
- ✅ Unit tests
- ✅ Comprehensive README
Quick start:
git clone https://github.com/Moshiour027/techyowls-branding.git
cd techyowls-branding/spring-boot-ai-starter
docker-compose up -d
./mvnw spring-boot:runConclusion
You’ve just built a production-ready AI application in Java! Here’s what we covered:
✅ Spring AI fundamentals and architecture
✅ Multi-provider chat completions (OpenAI + Ollama)
✅ Advanced RAG system with vector stores
✅ PostgreSQL pgvector integration
✅ Production features (metrics, error handling, health checks)
✅ Docker and Kubernetes deployment
Next Steps
- Add function calling: Let AI call your Java methods
- Implement caching: Reduce costs with Redis
- Add streaming responses: Real-time chat UX
- Build a UI: React/Angular frontend
- Scale horizontally: Kubernetes auto-scaling
Resources
FAQs
Q: Can I use Azure OpenAI instead?
A: Yes! Change dependencies to spring-ai-azure-openai-spring-boot-starter and update configuration.
Q: How much does this cost to run?
A: With gpt-4o-mini: ~$0.15/1M input tokens, $0.60/1M output tokens. Ollama is free.
Q: Can I use this in production?
A: Absolutely! Add rate limiting, caching, and monitoring for enterprise use.
Q: What about image generation?
A: Spring AI supports DALL-E. Add ImageClient similar to ChatClient.
Q: Performance concerns?
A: Vector search is fast (~ms). AI calls depend on provider (OpenAI: 1-3s, Ollama: faster but less accurate).
Found this helpful? Star the GitHub repo and follow TechyOwls for more Java + AI tutorials!
Questions? Drop a comment below or reach out on Twitter/X!
Published: December 7, 2024
Tags: #SpringAI #Java #SpringBoot #AI #RAG #OpenAI #Ollama #VectorStore
Advertisement
Moshiour Rahman
Software Architect & AI Engineer
Enterprise software architect with deep expertise in financial systems, distributed architecture, and AI-powered applications. Building large-scale systems at Fortune 500 companies. Specializing in LLM orchestration, multi-agent systems, and cloud-native solutions. I share battle-tested patterns from real enterprise projects.
Related Articles
The Visitor Design Pattern: Add Operations Without Modifying Classes
Master the Visitor Pattern in Java. Learn how to add new operations to object structures using double dispatch.
JavaThe Template Method Pattern: The Recipe for Success
Master the Template Method Pattern in Java. Learn how to define the skeleton of an algorithm in a superclass but let subclasses override specific steps.
JavaThe Strategy Design Pattern: Kill the If-Else Statements
Master the Strategy Pattern in Java. Learn how to replace complex if-else logic with interchangeable algorithms and follow the Open/Closed Principle.
Comments
Comments are powered by GitHub Discussions.
Configure Giscus at giscus.app to enable comments.