CAP Theorem Explained: The Distributed Systems Trade-Off Every Engineer Must Know
Master the CAP theorem for system design interviews. Understand Consistency, Availability, Partition Tolerance trade-offs with real database examples like MongoDB, Cassandra, DynamoDB.
Moshiour Rahman
Advertisement
What is the CAP Theorem?
The CAP theorem (also called Brewer’s theorem) is a fundamental principle in distributed systems that states:
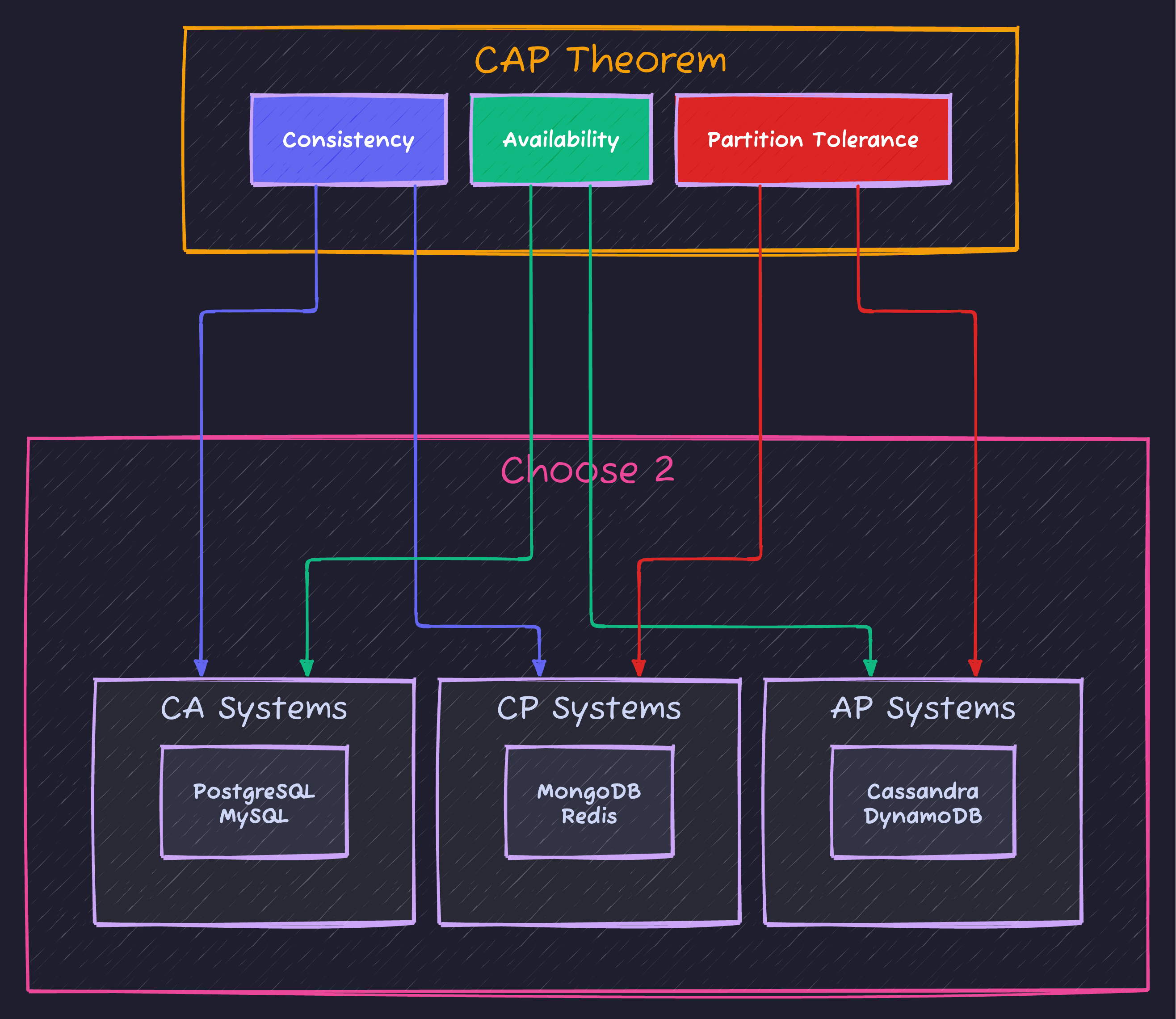
A distributed system can only guarantee two of three properties simultaneously: Consistency, Availability, and Partition Tolerance.
This theorem, proposed by Eric Brewer in 2000 and formally proven by Seth Gilbert and Nancy Lynch in 2002, shapes every architectural decision in modern distributed databases and microservices.
The Three Properties Explained
C - Consistency
Every read receives the most recent write or an error.
In a consistent system, all nodes see the same data at the same time. If you write data to one node, any subsequent read from any node returns that same data.
Client writes: balance = $100 → Node A
Client reads from Node B → Must return $100 (not $50 from before)Important: CAP’s “Consistency” is different from ACID’s “Consistency”:
- CAP Consistency = Linearizability (all nodes see same data)
- ACID Consistency = Data integrity constraints (foreign keys, validations)
A - Availability
Every request receives a non-error response, without guarantee that it contains the most recent write.
An available system always responds to requests. It never says “I’m too busy” or “Try again later.” Every node that receives a request must return a response.
Client request → System MUST respond (even if data might be stale)
❌ Timeout
❌ Error 503
✅ Response (possibly stale)P - Partition Tolerance
The system continues to operate despite network partitions between nodes.
A network partition occurs when nodes can’t communicate with each other. Messages are lost or delayed indefinitely. In real distributed systems, partitions are inevitable due to:
- Network failures
- Hardware issues
- Data center outages
- Submarine cable cuts

Why Can’t You Have All Three?
Here’s the key insight: Network partitions will happen. You can’t prevent them. So the real choice is:
When a partition occurs, do you:
- Sacrifice Consistency (AP) - Allow nodes to diverge, serve potentially stale data
- Sacrifice Availability (CP) - Refuse to serve requests until partition heals
The Proof (Simplified)
Imagine two nodes, A and B, with a network partition between them:
1. Client writes X=1 to Node A
2. Network partition happens (A can't talk to B)
3. Client reads X from Node B
What should Node B return?Option CP (Consistent): Node B says “I can’t guarantee I have the latest data, so I’ll return an error.” This sacrifices availability.
Option AP (Available): Node B returns its current value (maybe X=0, stale). This sacrifices consistency.
You cannot have both - Node B must choose.
CP vs AP: The Real Choice

Since partitions are unavoidable in distributed systems, you’re really choosing between:
CP Systems (Consistency + Partition Tolerance)
| Behavior | Example |
|---|---|
| Rejects writes during partition | Primary node unreachable = write fails |
| Returns error rather than stale data | ”Service unavailable” |
| Waits for quorum/consensus | Majority of nodes must agree |
Best for:
- Financial transactions (bank transfers)
- Inventory management (no overselling)
- Leader election (Zookeeper)
- Configuration management
Real-world CP databases:
| Database | How It Handles Partitions |
|---|---|
| MongoDB | Primary node must be reachable; secondaries become read-only |
| Redis Cluster | Minority partition becomes unavailable |
| HBase | RegionServer failure = region unavailable until failover |
| Zookeeper | Requires majority quorum to accept writes |
| etcd | Raft consensus requires majority |
AP Systems (Availability + Partition Tolerance)
| Behavior | Example |
|---|---|
| Always accepts writes | Even if nodes can’t communicate |
| May return stale data | Last known value, not latest |
| Syncs when partition heals | Conflict resolution needed |
Best for:
- Social media feeds (okay to see old posts briefly)
- Shopping carts (merge conflicts acceptable)
- Analytics and logging (some data loss okay)
- DNS (cached records are fine)
Real-world AP databases:
| Database | How It Handles Partitions |
|---|---|
| Cassandra | Each partition continues serving reads/writes |
| DynamoDB | Eventually consistent reads by default |
| CouchDB | Multi-master replication, conflict detection |
| Riak | Vector clocks for conflict resolution |
PACELC: The Extended Theorem
The CAP theorem only describes behavior during partitions. But what about normal operation? Enter PACELC:
If there is a Partition (P), choose between Availability (A) and Consistency (C); Else (E), when running normally, choose between Latency (L) and Consistency (C).
| System | During Partition | Normal Operation |
|---|---|---|
| MongoDB | PC (Consistent) | EC (Consistent, higher latency) |
| Cassandra | PA (Available) | EL (Low latency, eventual) |
| DynamoDB | PA (Available) | EL (Low latency by default) |
| PNUTS (Yahoo) | PC (Consistent) | EL (Low latency) |
This is why you’ll hear terms like “tunable consistency” - many databases let you choose the trade-off per operation.
Tunable Consistency in Practice
Modern databases don’t force a binary choice. You can tune consistency per query:
Cassandra Consistency Levels
-- Strong consistency (CP-like)
SELECT * FROM orders WHERE id = 123
WITH CONSISTENCY ALL;
-- Eventual consistency (AP-like)
SELECT * FROM users WHERE region = 'us-east'
WITH CONSISTENCY ONE;
-- Balanced (quorum)
INSERT INTO payments (id, amount) VALUES (1, 100)
WITH CONSISTENCY QUORUM;| Level | Replicas Needed | Trade-off |
|---|---|---|
ONE | 1 | Fastest, may be stale |
QUORUM | Majority | Balanced |
ALL | All replicas | Slowest, strongest |
MongoDB Read/Write Concerns
// Strong consistency
db.accounts.updateOne(
{ _id: 123 },
{ $inc: { balance: -100 } },
{ writeConcern: { w: "majority", j: true } }
);
// Fast but less durable
db.logs.insertOne(
{ event: "pageview", ts: new Date() },
{ writeConcern: { w: 1, j: false } }
);DynamoDB Consistency Options
# Eventually consistent (default, faster)
response = table.get_item(
Key={'id': '123'}
)
# Strongly consistent (2x cost, slower)
response = table.get_item(
Key={'id': '123'},
ConsistentRead=True
)Common Misconceptions
Misconception 1: “CA Systems Exist”
Wrong: “My PostgreSQL is CA - it’s consistent and available!”
Reality: A single-node database isn’t a distributed system. The moment you add replication or sharding, you must handle partitions. True CA systems can’t exist in practice because networks are unreliable.
Misconception 2: “You Pick Two Once and Forever”
Wrong: “We chose CP, so our whole system is CP.”
Reality: Different parts of your system can make different trade-offs. Your payment service might be CP while your recommendation engine is AP.
Misconception 3: “Consistency = Strong Consistency”
Wrong: “If a system is consistent, all reads return the latest write.”
Reality: There’s a spectrum of consistency models:
| Model | Description | Example |
|---|---|---|
| Linearizable | Strongest, real-time ordering | Zookeeper |
| Sequential | Operations ordered, not real-time | Most CP systems |
| Causal | Cause-effect relationships preserved | Some AP systems |
| Eventual | Will converge eventually | Cassandra, DynamoDB |
Misconception 4: “Partitions Are Rare”
Wrong: “We’re in a single data center, we don’t need to worry about partitions.”
Reality: Partitions happen constantly:
- Network switches fail
- Cables get unplugged
- Firewalls misconfigure
- GC pauses make nodes “disappear”
- AWS outages (they happen!)
Google’s Spanner paper reported that even with their internal network, they see partitions regularly.
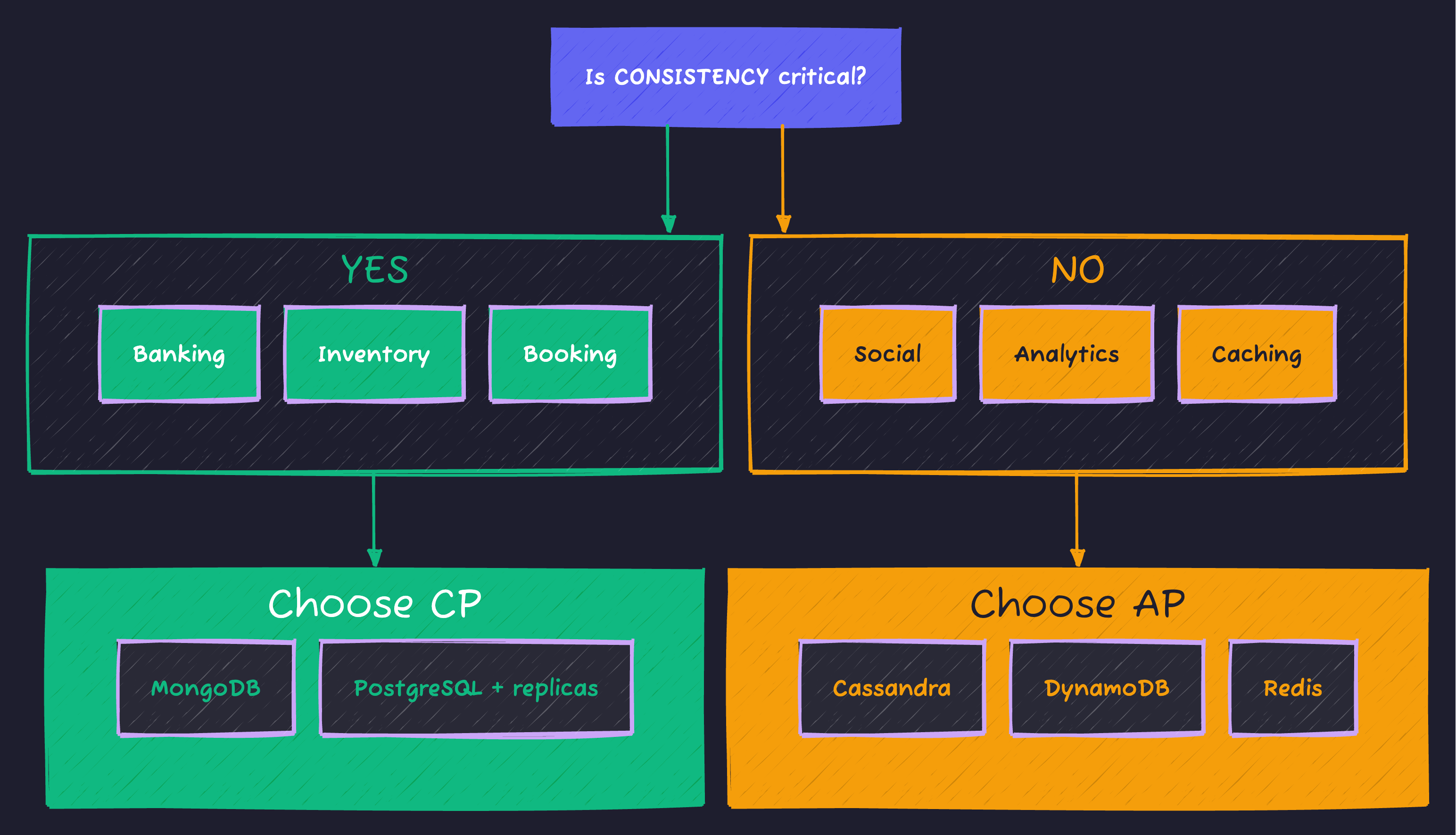
Decision Framework: What Should You Choose?
Use this mental model when designing systems:
Practical Examples
| Use Case | Choice | Why |
|---|---|---|
| Bank account balance | CP | Can’t show wrong balance |
| Airline seat booking | CP | Can’t oversell seats |
| Shopping cart | AP | Merge conflicts acceptable |
| Social media likes | AP | Slight delay is fine |
| Leader election | CP | Only one leader allowed |
| Session storage | AP | Worst case: re-login |
| Inventory count | CP | Can’t sell what you don’t have |
| User analytics | AP | Approximate counts okay |
Interview Questions & Answers
Q: “Explain CAP theorem in simple terms”
Strong Answer: “The CAP theorem says that in a distributed system, when a network partition happens, you must choose between consistency and availability. You can’t have both. If you choose consistency, the system might reject requests to avoid returning stale data. If you choose availability, the system always responds but might return outdated information. Since network partitions are inevitable in real systems, you’re essentially always choosing between CP and AP.”
Q: “Is MongoDB CP or AP?”
Strong Answer: “MongoDB is primarily CP. When a network partition isolates the primary node, writes are rejected until a new primary is elected. However, MongoDB offers tunable consistency - you can configure read preferences to read from secondaries, trading consistency for availability on reads. So it’s CP by default but can behave more AP-like for specific operations.”
Q: “How would you design a globally distributed database?”
Strong Answer: “I’d first identify which data requires strong consistency versus eventual consistency. For example:
- User authentication tokens: CP - can’t have stale tokens
- User profile data: AP - eventual consistency is acceptable
- Financial transactions: CP with synchronous replication
- Activity feeds: AP with conflict-free replicated data types (CRDTs)
I’d use a database that supports tunable consistency like Cassandra or CockroachDB, setting appropriate consistency levels per query type. For global distribution, I’d consider PACELC trade-offs - accepting higher latency for cross-region consistency where needed.”
Q: “What’s the difference between CAP consistency and ACID consistency?”
Strong Answer: “They’re completely different concepts:
-
CAP Consistency (Linearizability): All nodes in a distributed system see the same data at the same time. It’s about replication and distributed state.
-
ACID Consistency: Database transitions from one valid state to another. It’s about data integrity - foreign keys, constraints, triggers.
A system can be ACID-consistent (all constraints satisfied) but CAP-inconsistent (replicas have different data). And vice versa.”
Quick Reference Card
╔══════════════════════════════════════════════════════════════╗
║ CAP THEOREM CHEAT SHEET ║
╠══════════════════════════════════════════════════════════════╣
║ ║
║ C = CONSISTENCY ║
║ All nodes see same data at same time ║
║ Every read returns most recent write (or error) ║
║ ║
║ A = AVAILABILITY ║
║ Every request gets a response ║
║ No timeouts, no errors (but maybe stale data) ║
║ ║
║ P = PARTITION TOLERANCE ║
║ System works despite network failures ║
║ Required in any real distributed system ║
║ ║
╠══════════════════════════════════════════════════════════════╣
║ ║
║ THE REALITY: Partitions happen. Choose CP or AP. ║
║ ║
║ CP SYSTEMS │ AP SYSTEMS ║
║ ────────────────────┼──────────────────── ║
║ MongoDB │ Cassandra ║
║ Redis Cluster │ DynamoDB ║
║ HBase │ CouchDB ║
║ Zookeeper │ Riak ║
║ etcd │ DNS ║
║ │ ║
║ Use for: │ Use for: ║
║ • Banking │ • Social feeds ║
║ • Inventory │ • Shopping carts ║
║ • Leader election │ • Analytics ║
║ ║
╠══════════════════════════════════════════════════════════════╣
║ ║
║ PACELC (Extended): ║
║ If Partition → A vs C ║
║ Else (normal) → Latency vs Consistency ║
║ ║
║ TUNABLE CONSISTENCY: ║
║ Cassandra: ONE < QUORUM < ALL ║
║ MongoDB: w:1 < w:majority < w:all ║
║ DynamoDB: Eventually < Strongly consistent ║
║ ║
╚══════════════════════════════════════════════════════════════╝Summary
| Concept | Key Point |
|---|---|
| CAP Theorem | Can only guarantee 2 of 3: Consistency, Availability, Partition Tolerance |
| Reality | Partitions happen, so you choose CP or AP |
| CP Systems | Sacrifice availability for correctness (MongoDB, Zookeeper) |
| AP Systems | Sacrifice consistency for uptime (Cassandra, DynamoDB) |
| PACELC | Extends CAP to include latency trade-offs in normal operation |
| Tunable | Modern databases let you choose per-operation |
| Key Insight | Different parts of your system can make different trade-offs |
The CAP theorem isn’t about limitations - it’s about making informed trade-offs. Understanding it helps you design systems that behave correctly under real-world conditions, not just in ideal scenarios.
Further Reading
Advertisement
Moshiour Rahman
Software Architect & AI Engineer
Enterprise software architect with deep expertise in financial systems, distributed architecture, and AI-powered applications. Building large-scale systems at Fortune 500 companies. Specializing in LLM orchestration, multi-agent systems, and cloud-native solutions. I share battle-tested patterns from real enterprise projects.
Related Articles
Microservices Design Patterns: Complete Architecture Guide
Master microservices architecture patterns. Learn service discovery, circuit breakers, saga pattern, API gateway, and build resilient distributed systems.
System DesignAPI Design Part 1: HTTP & REST Fundamentals
Master HTTP methods, status codes, and REST maturity model. The foundation every API developer needs - from GET/POST basics to idempotency and proper status code selection.
System DesignAPI Design Part 4: Versioning & Idempotency
Master API versioning strategies and idempotency patterns. Learn URL vs header versioning, version lifecycle management, and Stripe-style idempotency keys for reliable APIs.
Comments
Comments are powered by GitHub Discussions.
Configure Giscus at giscus.app to enable comments.